交通环境风速预测SPARK大数据嵌入方法
指导老师 刘辉
2020年06月05日
Big data embedding method based on Spark for wind speed prediction in traffic environment

交设1604班 李烨
交通环境风速预测SPARK大数据嵌入方法
Big data embedding method based on Spark for wind speed prediction in traffic environment
PART ONE
铁路运输:
铁路沿线强风会导致列车晚点、停运、侧翻事故,并会造成桥梁、接触网、通信设施等基础设施的严重受损。此外,由于高速列车的运行速度快,轴重轻,其运行安全更容易收到强风的影响,导致列车横向的失稳并有可能发生倾覆。
航空运输:
机场地面强风会影响运行方向的选择并对航空器起降活动安全构成威胁。机场地面和近地空间风速风向的突然改变造成的风切变现象也对航空器起降造成严重危害。



交通环境风速
交通环境风速预测SPARK大数据嵌入方法
Big data embedding method based on Spark for wind speed prediction in traffic environment
PART TWO
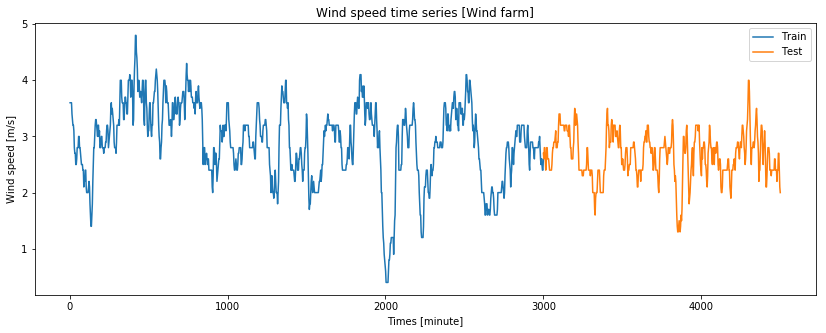
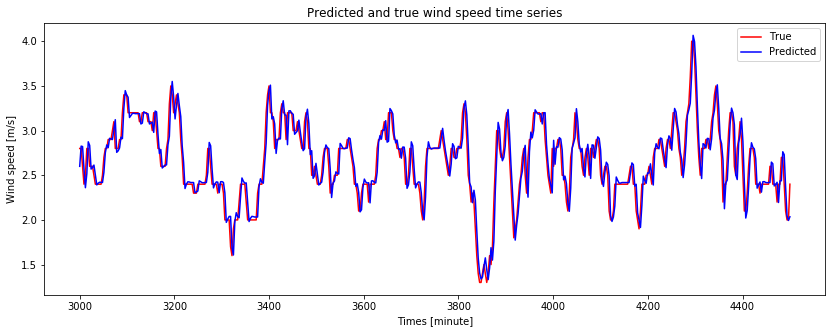
时间序列:
时间序列是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。
时间序列预测:
时间序列分析的主要目的是根据已有的历史数据对未来进行预测。
预测
时间序列预测:
时间序列分析的主要目的是根据已有的历史数据对未来进行预测。
预测
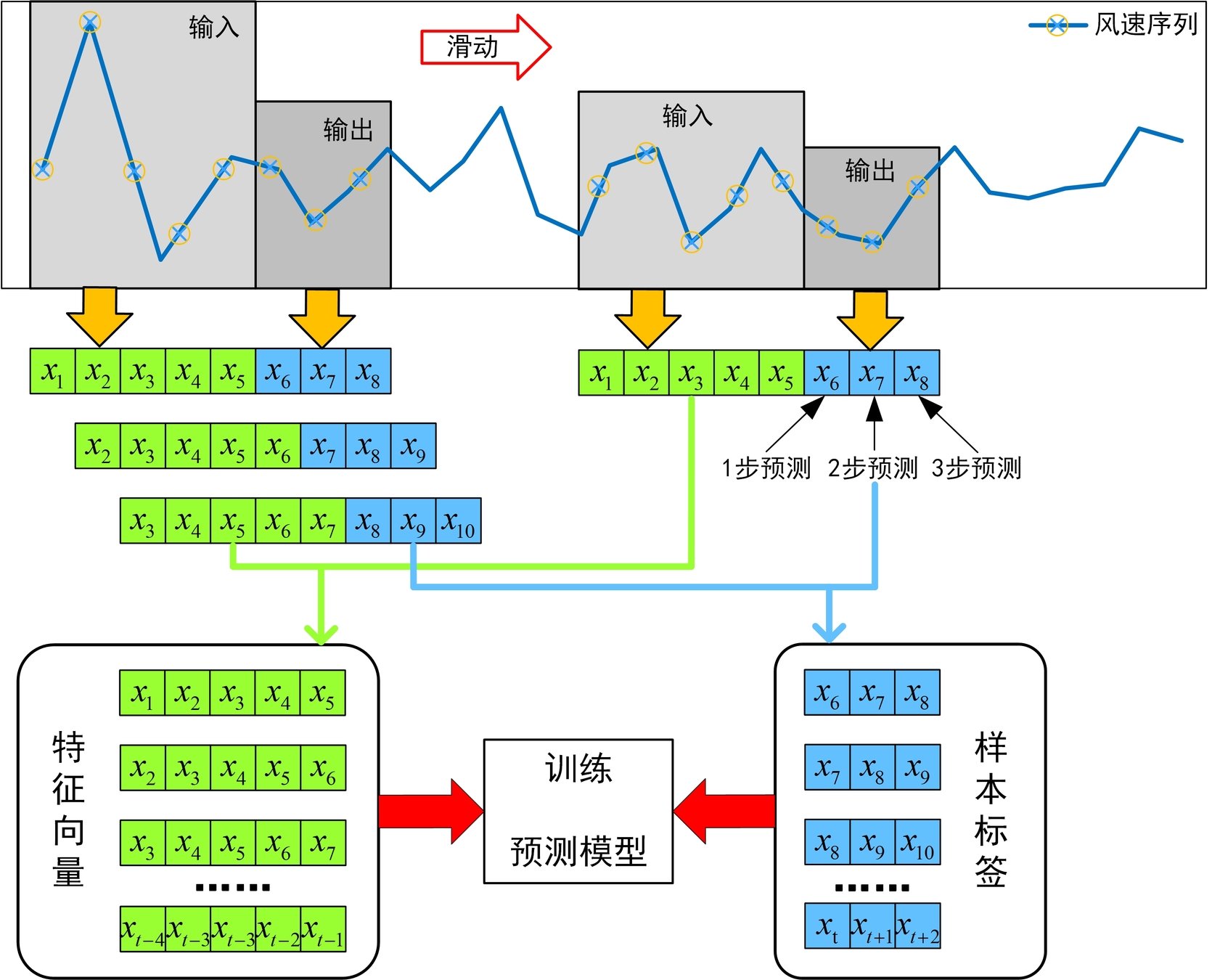
预测模型:
基于机器学习和深度学习中用于处理回归问题的方法可以构建用于时间序列预测的模型。
\widehat{\mathbf{y}}=f\left ( \mathbf{x} \right )
历史值
预测值
预测模型
交通环境风速预测SPARK大数据嵌入方法
Big data embedding method based on Spark for wind speed prediction in traffic environment
PART THREE
Apache Spark
Spark是一款开源的用于大规模数据处理的分析引擎和集群计算系统。
SPARK大数据
MLlib
MLlib是 Spark内置的机器学习库,它可以实现基于大数据的机器学习,使得机器学习在全量数据上的学习成为可能。
MLlib提供的机器学习算法涉及到特征工程、分类、回归、聚类等多个方面。
-
高效:基于内存计算,较Hadoop快100倍
-
易用:Java、Scala、Python、R、SQL等语言
-
通用:交互式查询、流计算、机器学习、图计算
-
兼容:支持多种调度器和不同数据源

Spark生态
Spark特性
交通环境风速预测SPARK大数据嵌入方法
Big data embedding method based on Spark for wind speed prediction in traffic environment
PART FOUR
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
基于SPARK大数据风速预测模型的构建、训练及评估
风速预测模型部署主要流程
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
数据来源:
风速数据源于新疆维吾尔自治区乌鲁木齐市达坂城区,其测量单位为米/秒,测量间隔为3分钟。
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
Spark环境构建
基于机器学习和深度学习的风速预测模型将分别在本地环境和云集群环境进行训练、测试及对比。
本地环境
本地环境用于实现基于MLlib的机器学习算法,该Spark环境部署在Linux系统。
云集群环境
集群环境用于实现基于Keras的深度学习算法,该Spark环境基于数据分析平台Databricks搭建。
liye@liye-virtual-machine:~$ spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://192.168.31.188:4040
Spark context available as 'sc' (master = local[*], app id = local-1591105423828).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.0
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_252)
Type in expressions to have them evaluated.
Type :help for more information.嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
数据分解
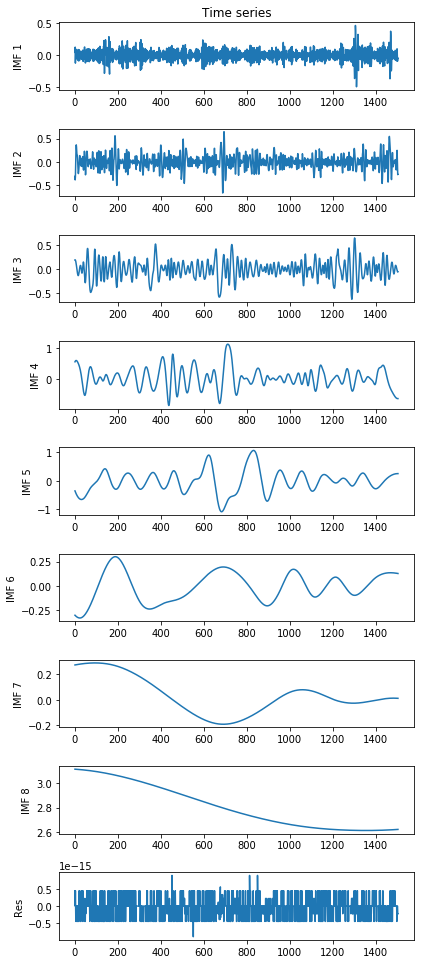
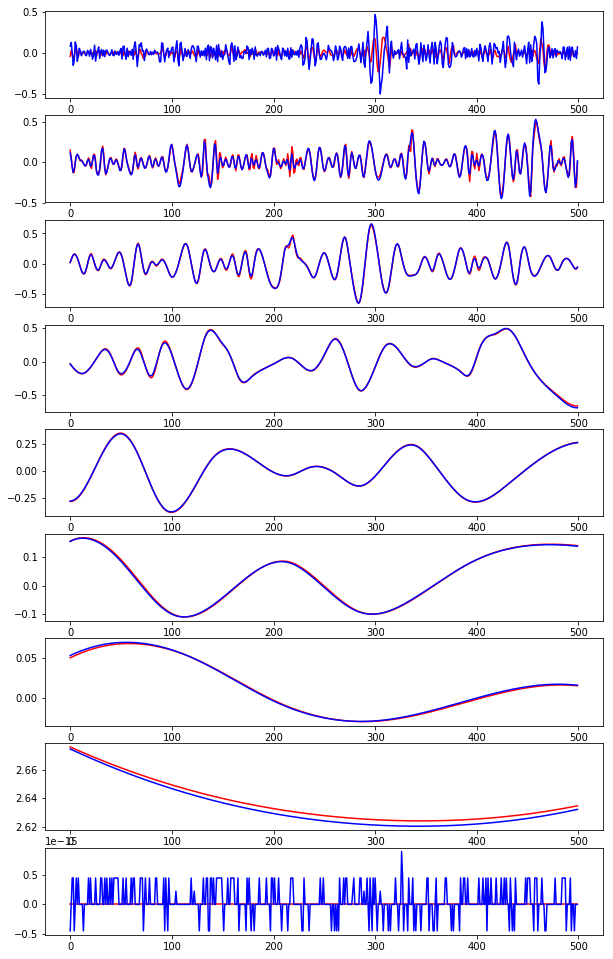
将复杂的原始时间序列分解为多个不同频率分量的子序列并分别预测,是提预测性能的重要途径。
经验模态分解
经验模态分解(EMD)适用于分析非静态、非线性、非平稳过程产生的数据,因而选用该算法及其改进版本(CEEMDAN)用于波动性强、非线性高的风速时间序列的分解。
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估

嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
预测模型:
选用四种机器学习算法(线性回归、决策树回归、随机森林回归、梯度提升树回归)和一种深度学习算法(长短期记忆网络)用于构建风速预测模型。

基于MLlib实现;SCALA语言
基于Keras实现;PYTHON语言
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估



-
线性回归
-
决策树
-
随机森林
-
梯度提升树
模型选择和管道模型
四种机器学习模型使用Spark组件MLlib提供的方法实现。为确定最佳模型参数,使用MLlib提供的K折交叉验证算法进行模型选择。
各预测模型均嵌入在Spark为机器学习提供的Pipeline机器学习管道中,它允许将机器学习中各个算法由统一的接口连接起来,并嵌入到一个统一的管道模型中。
K折交叉验证
该算法遍历指定的全部参数组合,并对任一组合计算K个泛化误差,选择平均误差最低的模型作为最优模型。
机器学习模型
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
| 网络层 | 类型 | 单元数 | 参数个数 | 描述 |
|---|---|---|---|---|
| 输入层 | - | - | - | 获取输入序列 |
| 隐藏层 | LSTM层 | 100 | 42400 | 获取序列特征 |
| 隐藏层 | LSTM层 | 100 | 80400 | 获取序列特征 |
| 隐藏层 | Dense层 | 100 | 10100 | 解释序列特征 |
| 输出层 | Dense层 | 1 | 101 | 输出预测结果 |
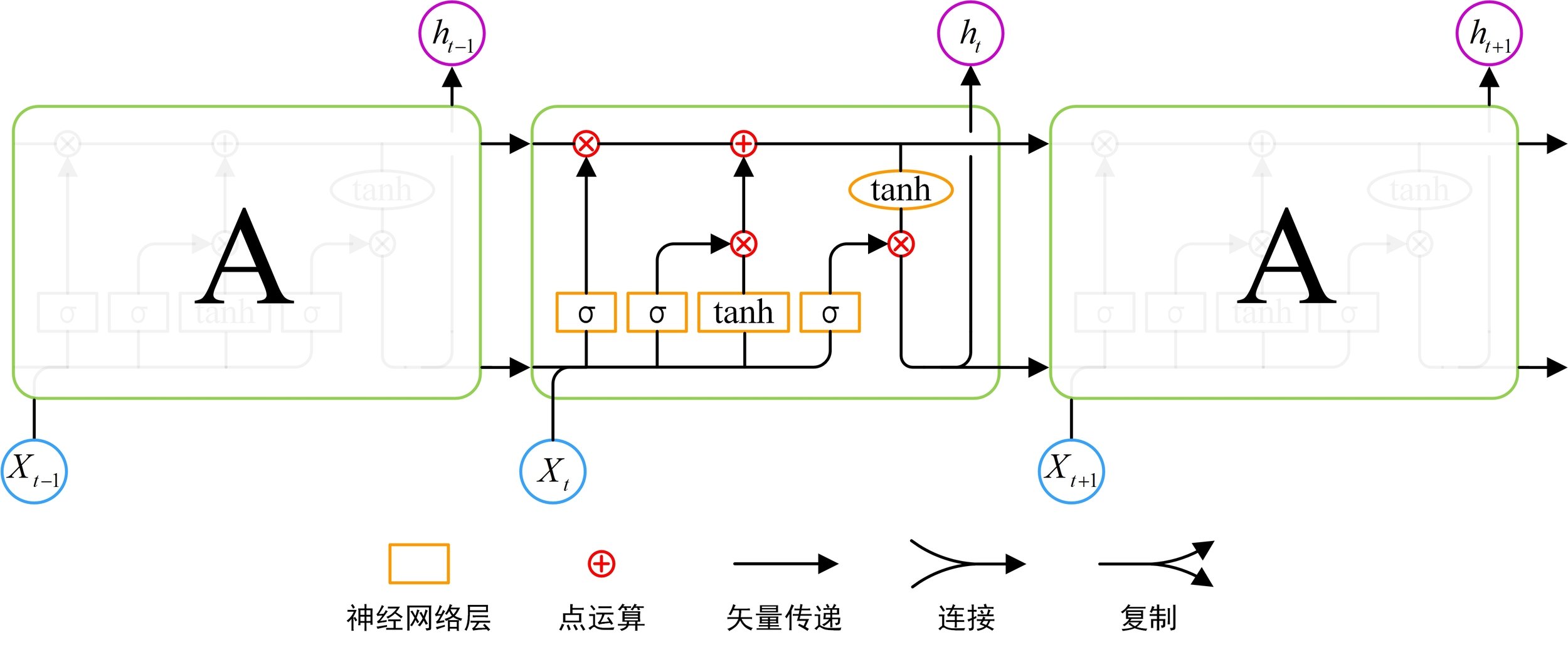
LSTM单元结构
LSTM模型结构
长短期记忆网络
长短期记忆网络(LSTM)是一种特殊的循环神经网络,它具有学习序列数据中长期依赖关系的能力,在时间序列预测问题上应用广泛。
网络模型结构
LSTM 模型包括 2 个 LSTM 隐藏层以及两个 Dense 全连接层。LSTM 层用于序列的输入及其特征的获取,而Dense 层负责解释特征和输出结果。
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
机器学习模型训练
给定候选参数网格,交叉验证器参数,由算法自动进行最优模型选择及训练。
深度学习模型训练
给定模型训练参数,由算法自动进行迭代求解最终给出模型。
| 参数类型 | 参数取值 |
|---|---|
| 预测模型 | LR/DT/RF/GBDT |
| 评估模型 | 均方根误差 |
| 参数网格 | 依具体参数类型指定 |
| 并行参数 | 4 |
| 子集个数 | 10 |
交叉验证器参数
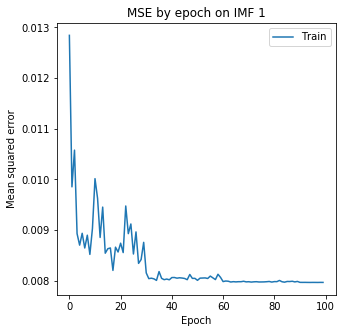
LSTM模型训练参数
| 参数类型 | 参数取值 |
|---|---|
| 迭代次数 | 100 |
| 学习率 | 0.001(-10%/30次) |
| 损失函数 | 均方误差 |
| 优化器 | Adam |
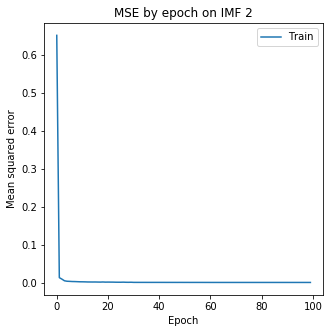
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
预测值-真值曲线图
-
各预测结果均相对原始序列有滞后;
-
基于分解的预测误差波动幅度明显降低;
-
基于分解的预测在突变点附近性能较差;
观察左图可得以下结论:
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
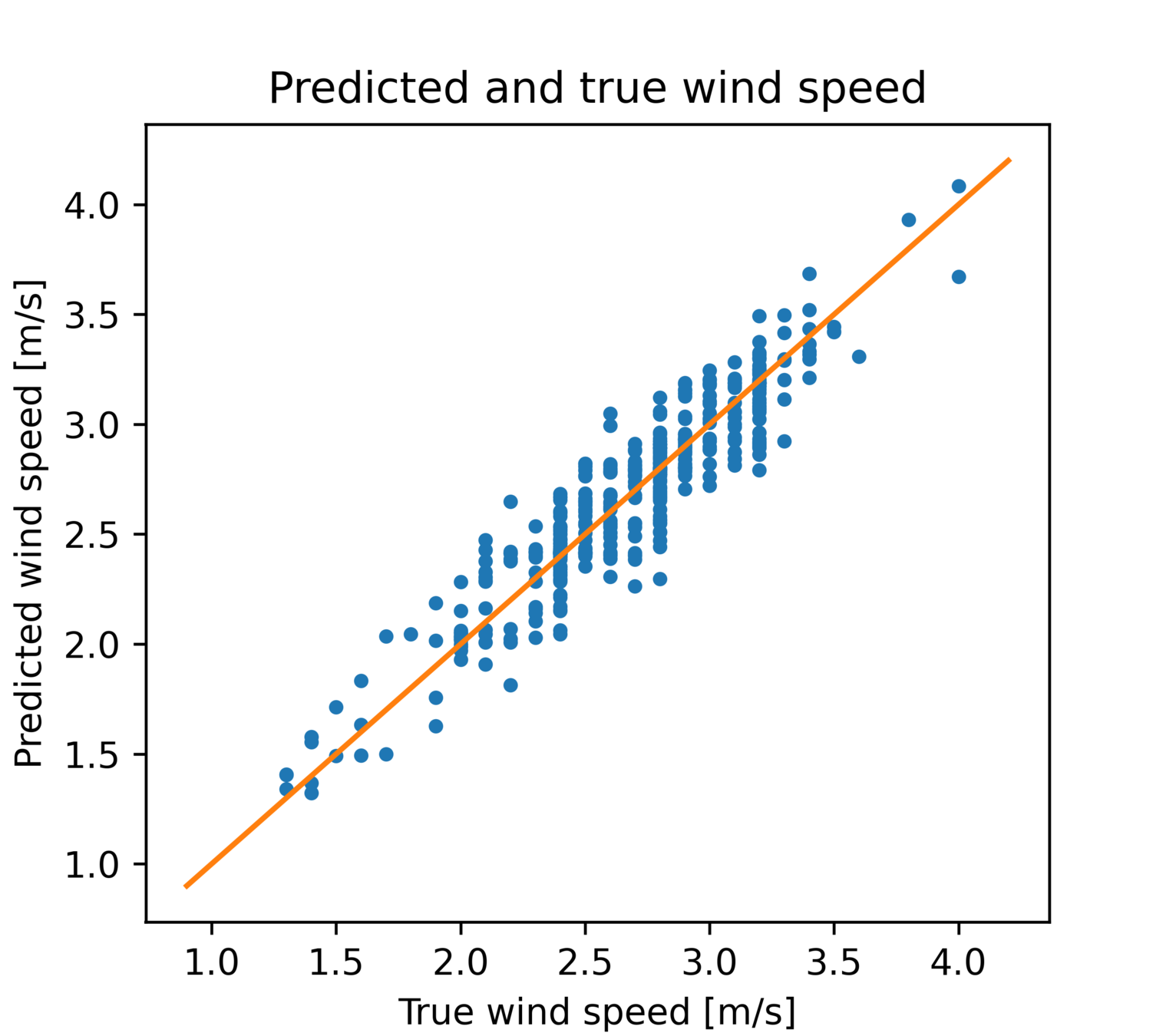
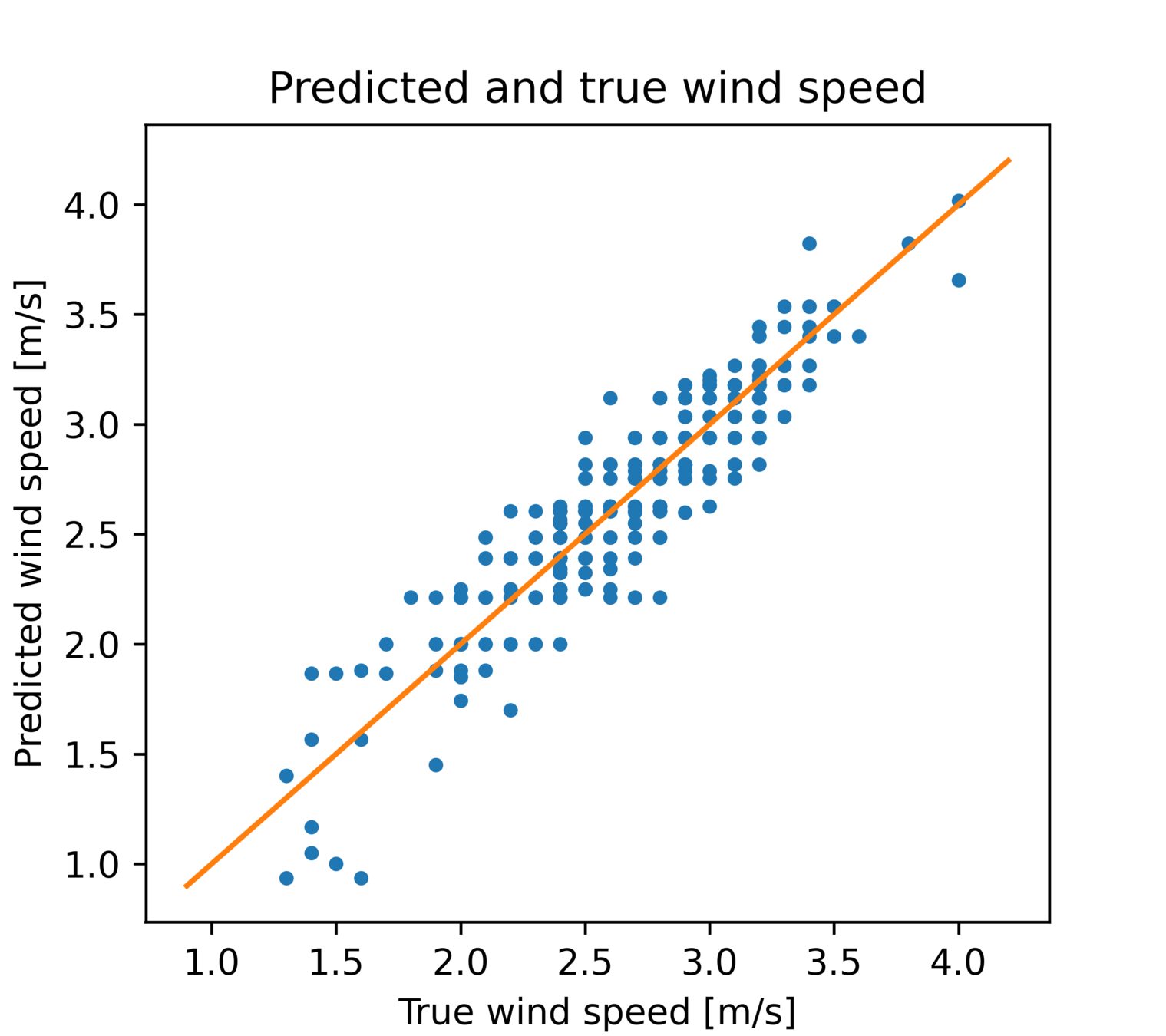
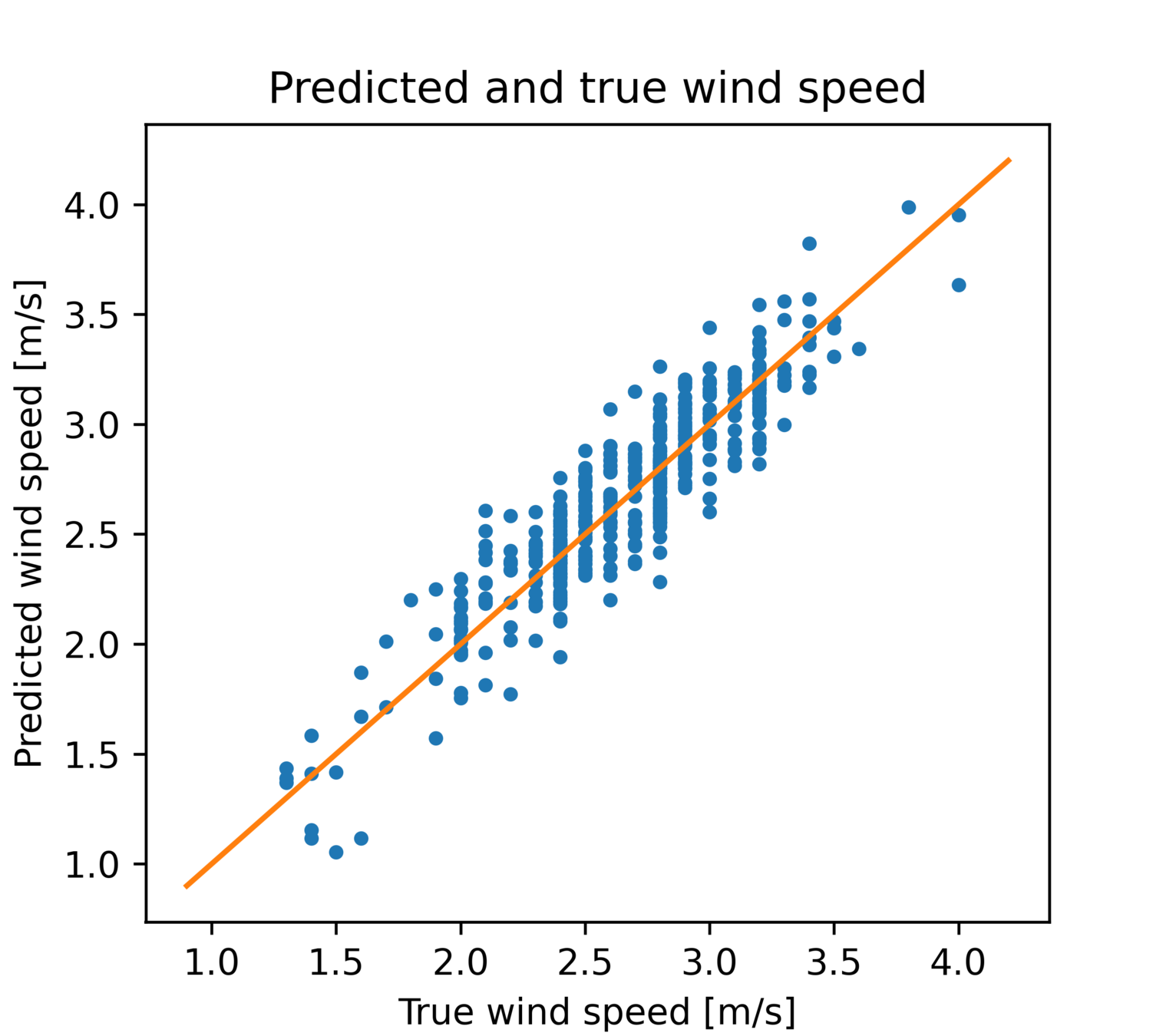
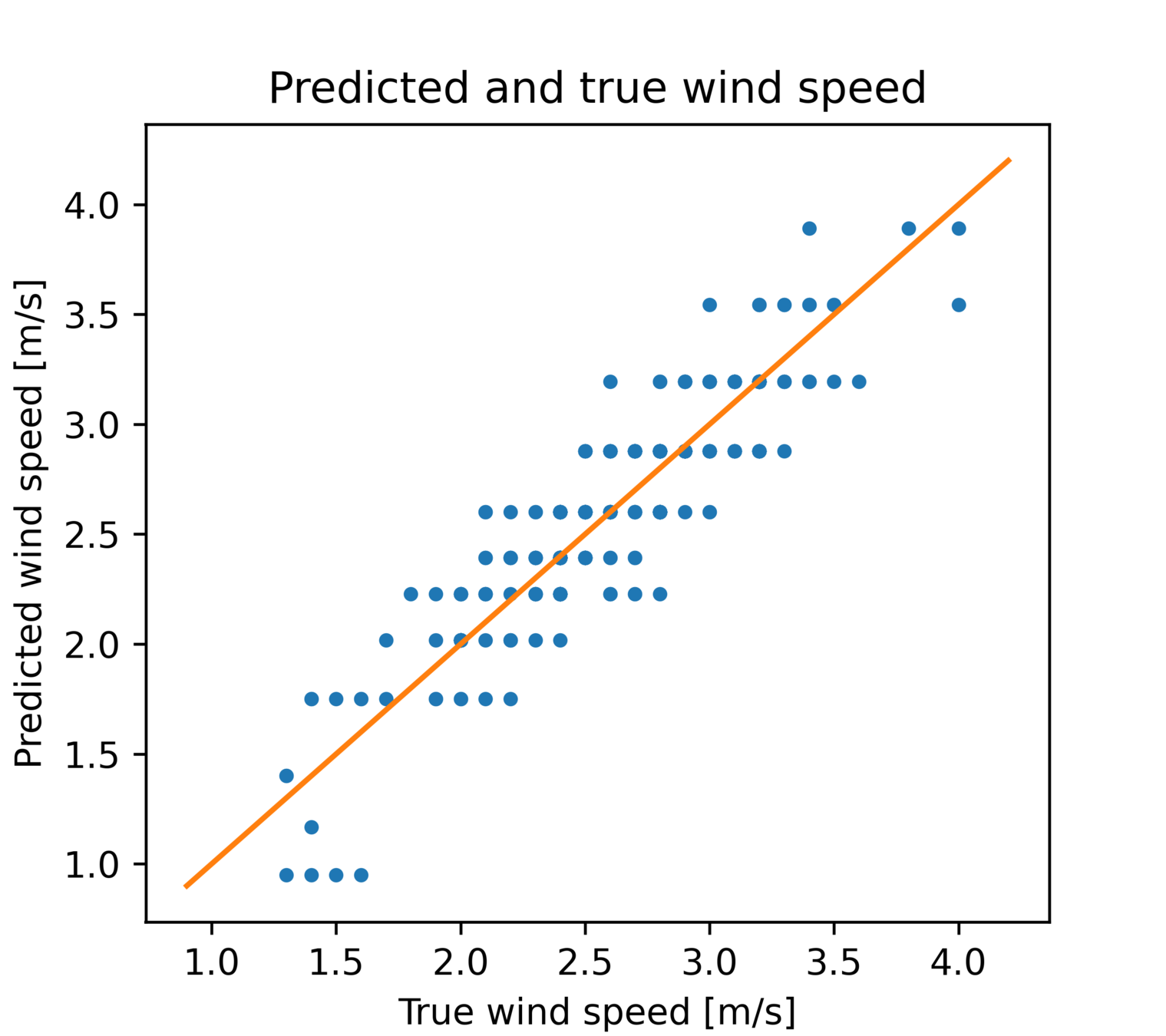
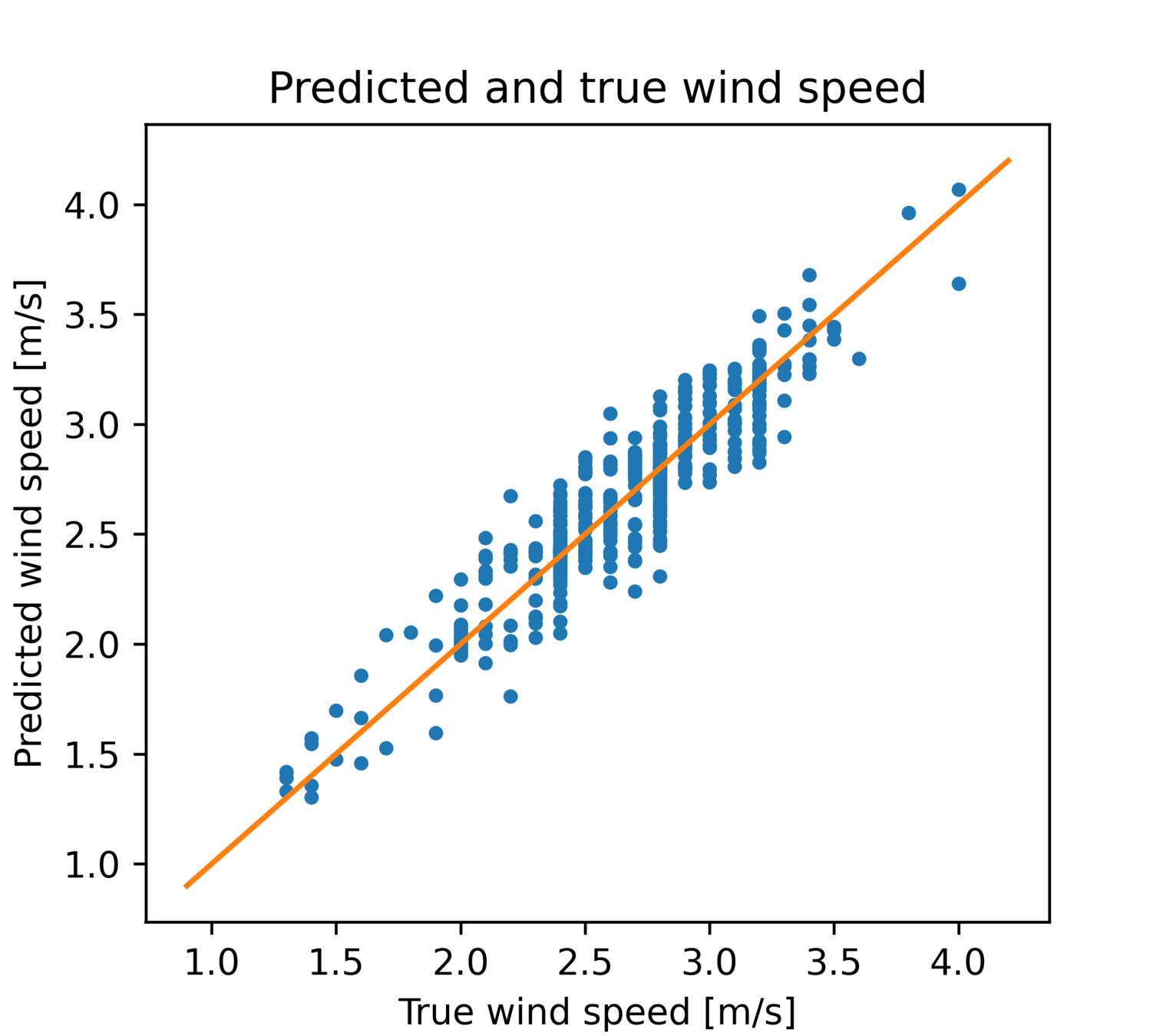
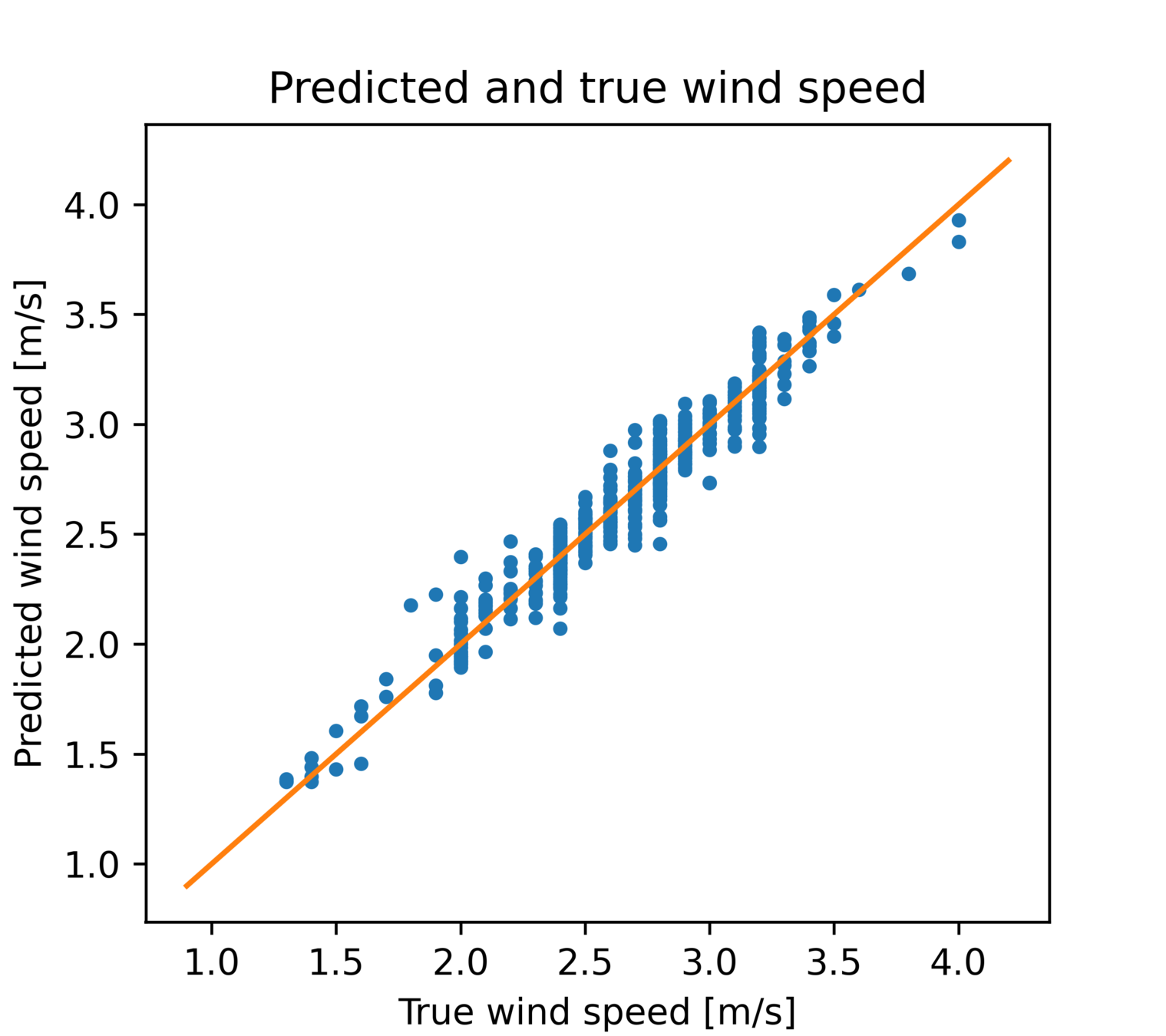
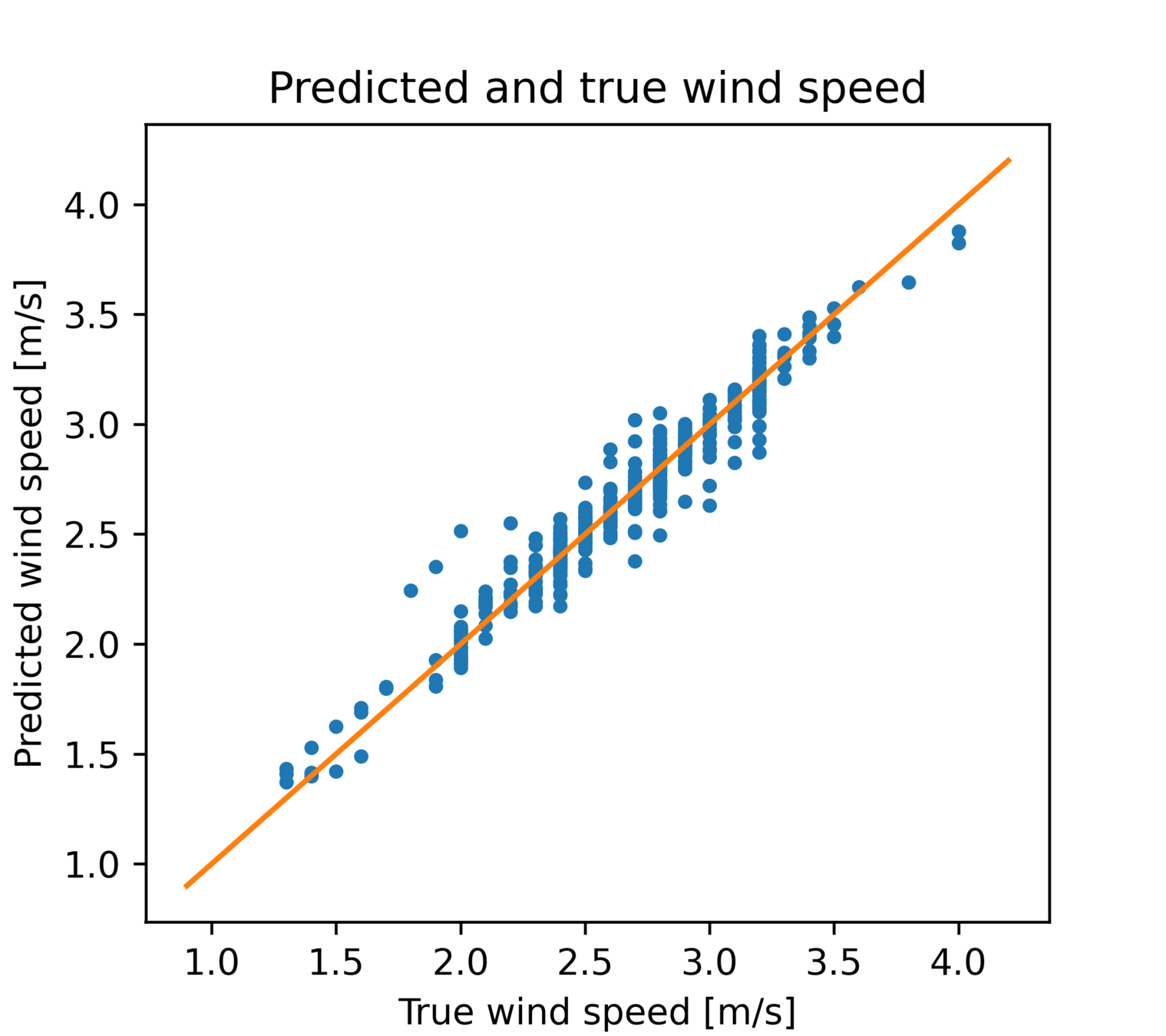
线性回归
决策树
随机森林
梯度提升树
LSTM
EMD-LSTM
CEEMDAN-LSTM
预测值-真值散点图
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
评价角度
从预测模型准确性、稳定性、效率三个方面对预测模型性能进行评价。
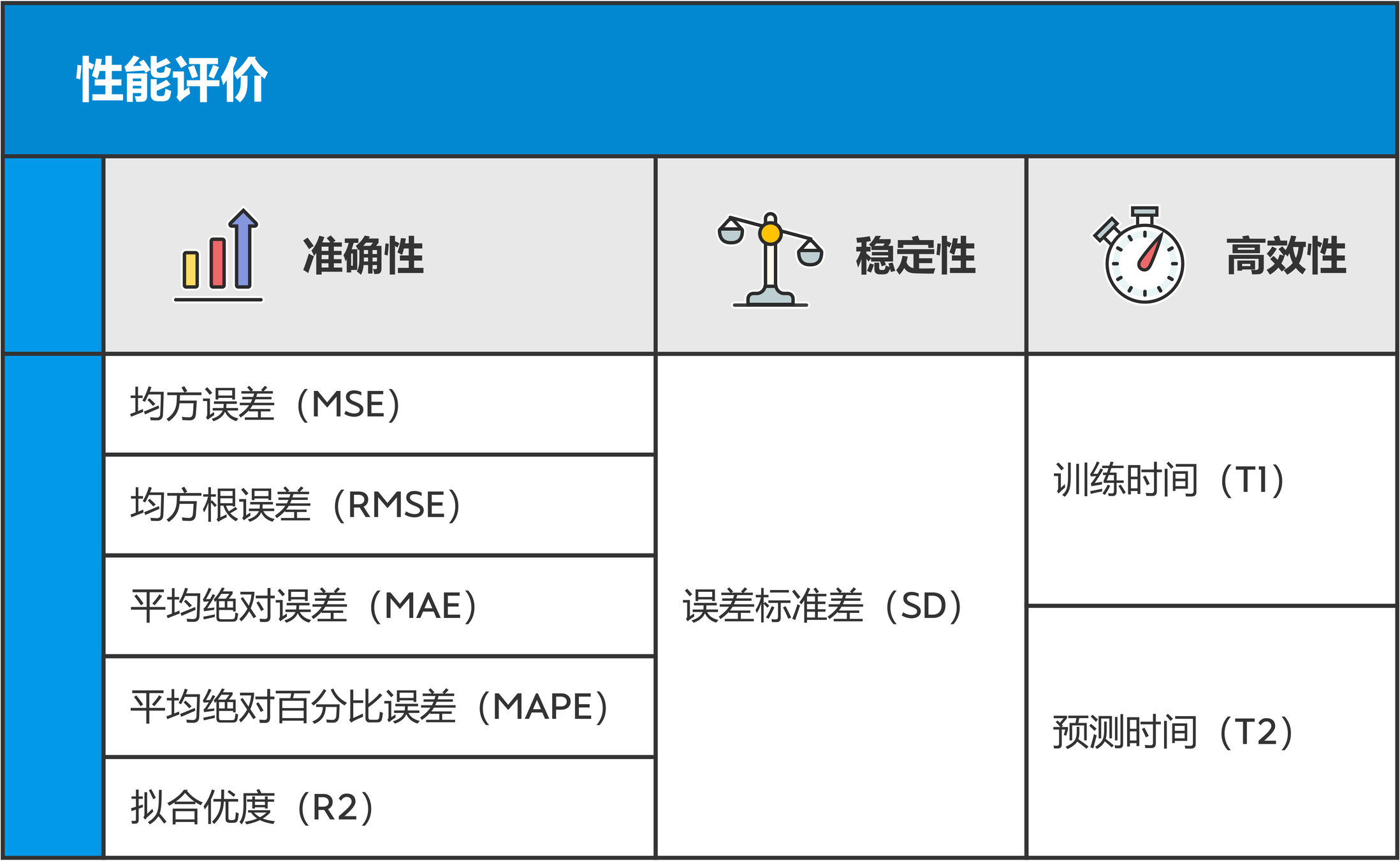
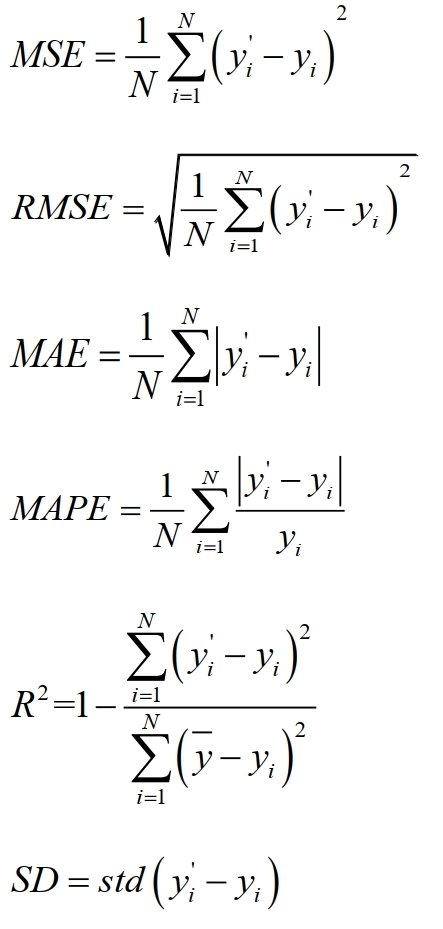
评价指标
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
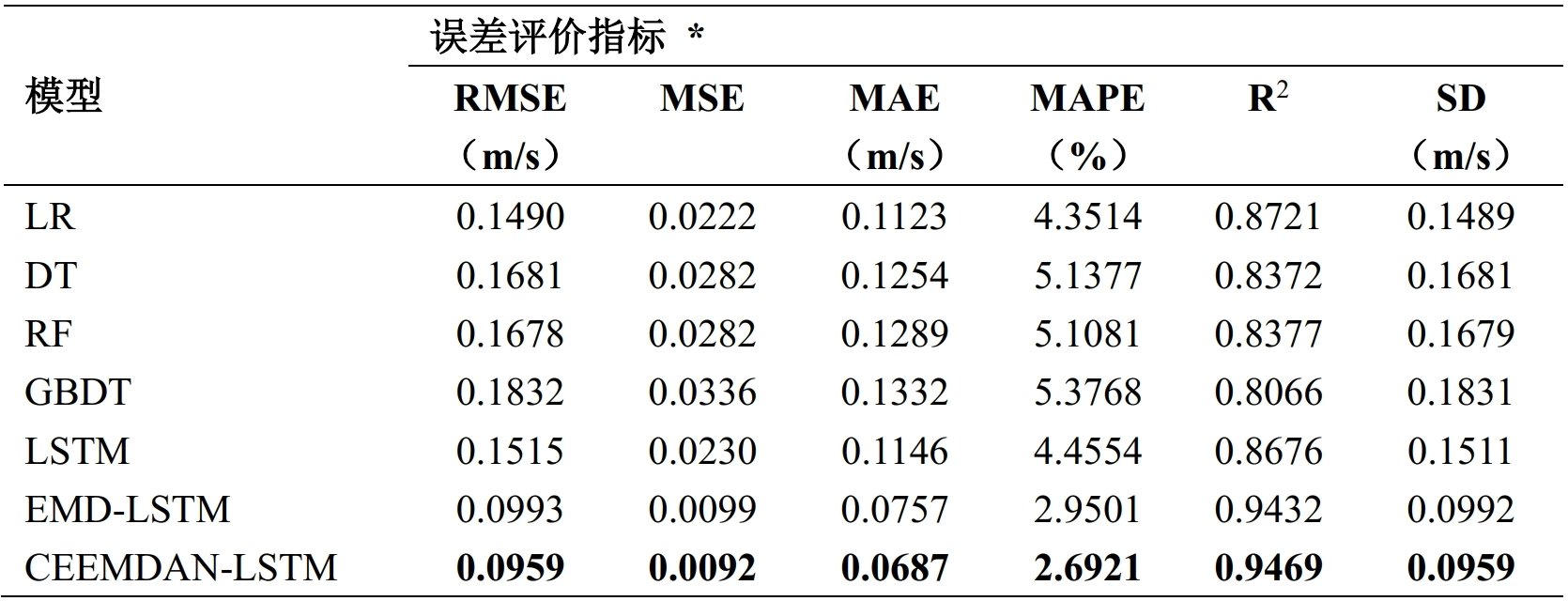
误差评价指标
* 各指标中性能最优的数值以粗体格式标注
在各项误差指标上, CEEMDAN-LSTM 模型均有最好的评价,证明了该预测模型的有效性。
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
-
基于树和树集成的预测模型的性能最差;
-
经K折交叉验证进行模型选择得到的多元线性回归模型的性能已与LSTM模型相近;
-
基于分解的预测模型均优于其他模型;
-
CEEMDAN-LSTM性能最佳
观察右图可得以下结论:
最小化目标
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
-
树集成技术性能最差
-
CEEMDAN-LSTM性能最优
观察右图可得以下结论:
拟合优度(Goodness of Fit)
RMSE,MSE考量预测值和实测值间的误差,受物理量纲影响。拟合优度R^2考量预测值与基准模型预测值间的偏差,能够更精确的反应模型的性能。
最大化目标
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
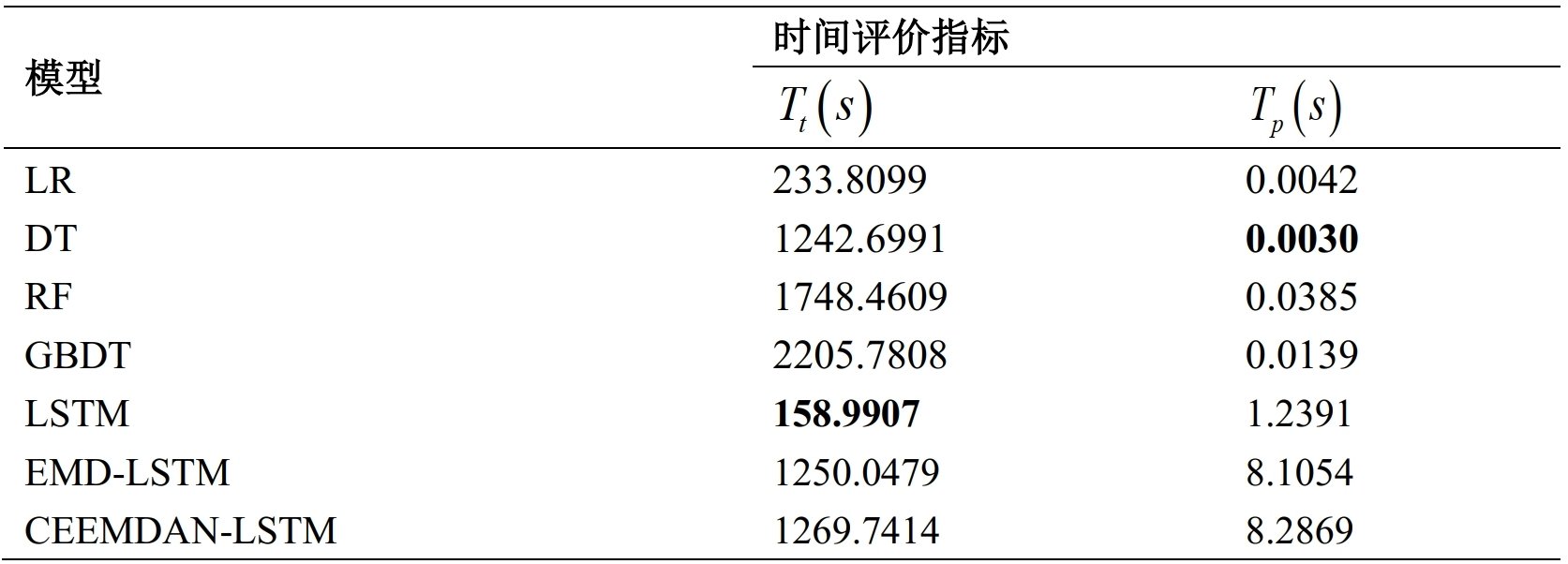
时间评价指标
* 各指标中性能最优的数值以粗体格式标注
训练时间上LSTM模型耗时最少,由于在该模型中仅训练了一个LSTM网络,而其他模型均使用了交叉验证算法或分解技术,因此该现象合理。预测时间上决策树模型耗时最低,考虑到该模型原理和实现的简洁性,该现象合理。
嵌入方法
数据获取
环境构建
数据分解
模型构建
模型训练
模型测试
性能评估
-
模型选择算法和分解算法的引入会导致训练时间的急剧增加,这与模型数量大相适应;
-
基于机器学习的模型预测时间普遍较短,这与其模型复杂性低相适应;
-
基于深度学习的模型预测时间普遍较长,这与其模型复杂度高相适应。
观察上图可得以下结论:
结论及展望
-
构建了可在分布式环境运行的基于大数据的风速预测模型;
-
分析对比了多种机器学习模型和深度学习模型的预测性能;
-
利用模型选择算法以及分解算法实现了对预测性能的优化。
结论
展望
-
在实际分布式集群计算节点上的部署;
-
在线流式计算的引入以处理实时采集得到的海量数据流;
-
智能优化技术的引入以及序列前后处理技术的优化。
